2.1. Model Library Overview¶
2.1.1. Overview¶
Based on the ImageNet1k classification dataset, the 23 classification network structures supported by PaddleClas and the corresponding 117 image classification pretrained models are shown below. Training trick, a brief introduction to each series of network structures, and performance evaluation will be shown in the corresponding chapters.
2.1.2. Evaluation environment¶
- CPU evaluation environment is based on Snapdragon 855 (SD855).
- The GPU evaluation environment is based on V100 and TensorRT, and the evaluation script is as follows.
#!/usr/bin/env bash
export PYTHONPATH=$PWD:$PYTHONPATH
python tools/infer/predict.py \
--model_file='pretrained/infer/model' \
--params_file='pretrained/infer/params' \
--enable_benchmark=True \
--model_name=ResNet50_vd \
--use_tensorrt=True \
--use_fp16=False \
--batch_size=1
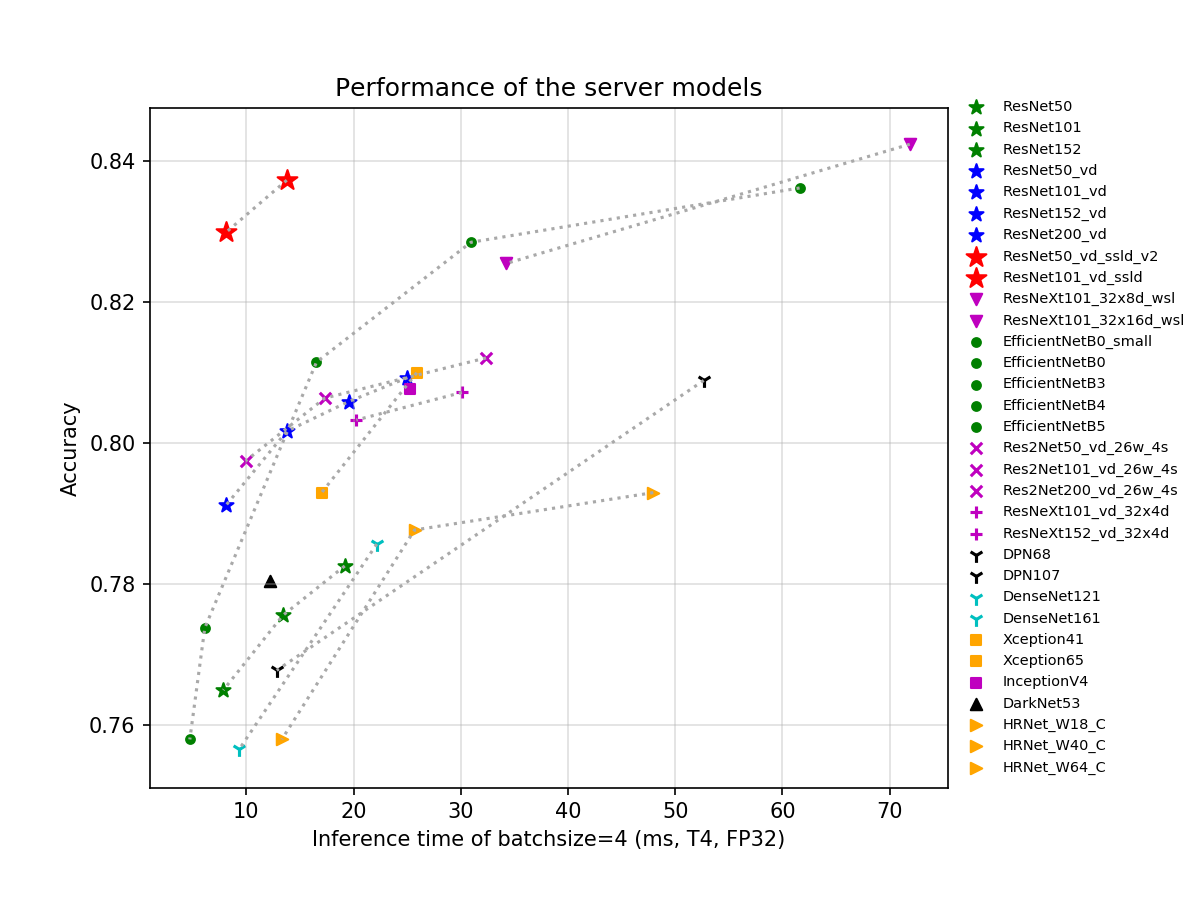
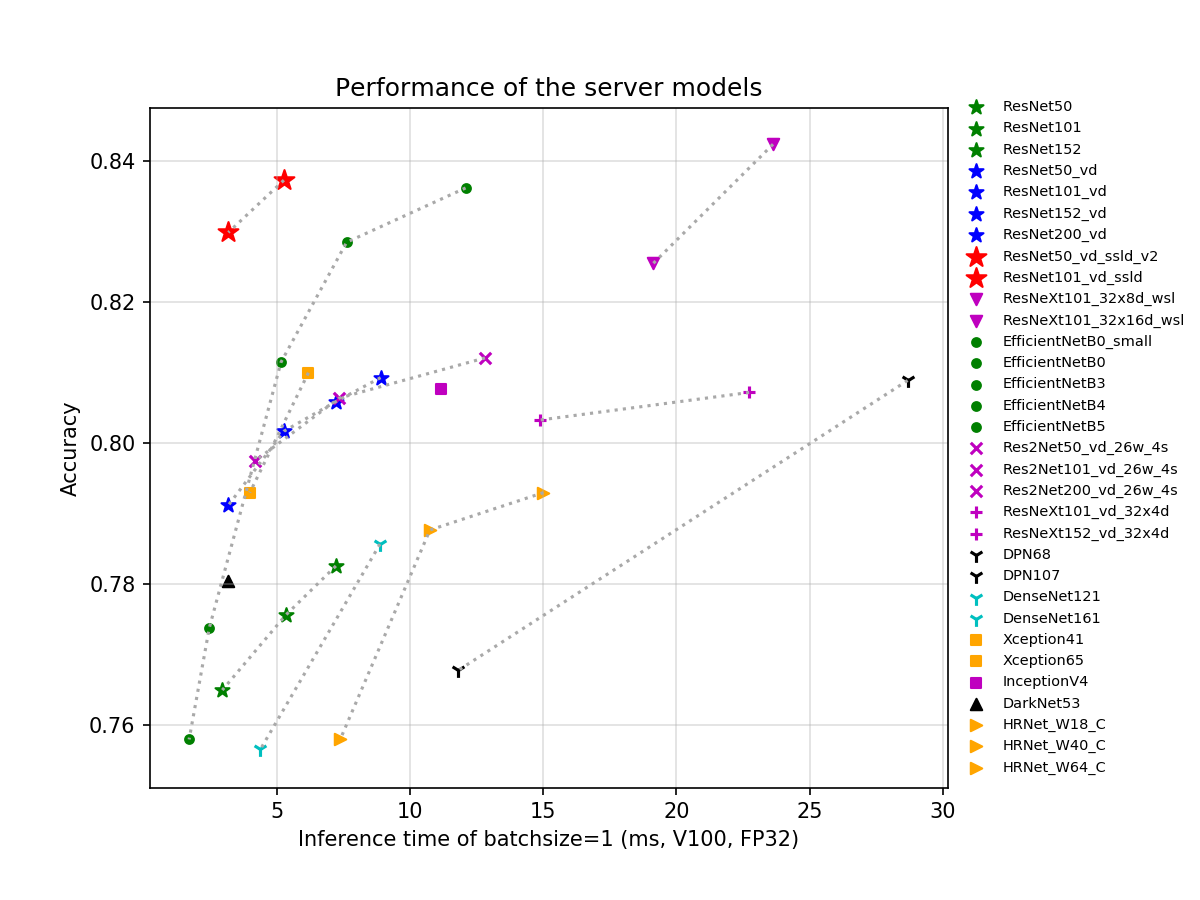
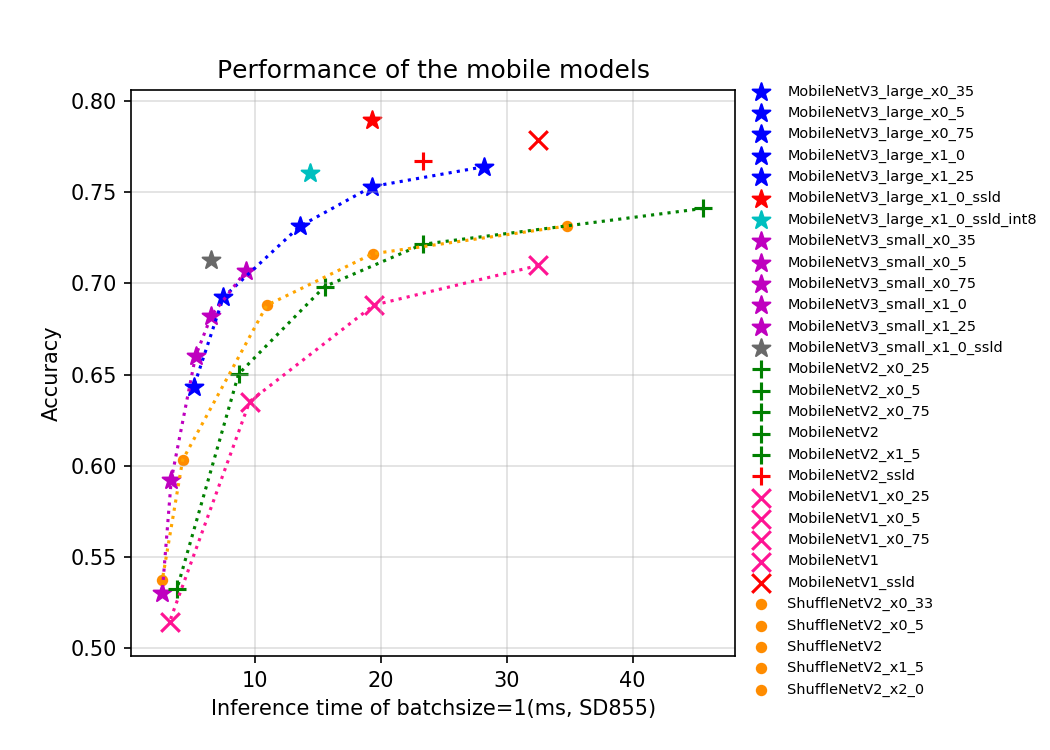
If you think this document is helpful to you, welcome to give a star to our project:https://github.com/PaddlePaddle/PaddleClas
2.1.3. Pretrained model list and download address¶
- ResNet and ResNet_vd series
- ResNet series[1](paper link)
- ResNet_vc、ResNet_vd series[2](paper link)
- Mobile and Embedded Vision Applications Network series
- MobileNetV3 series[3](paper link)
- MobileNetV3_large_x0_35
- MobileNetV3_large_x0_5
- MobileNetV3_large_x0_75
- MobileNetV3_large_x1_0
- MobileNetV3_large_x1_25
- MobileNetV3_small_x0_35
- MobileNetV3_small_x0_5
- MobileNetV3_small_x0_75
- MobileNetV3_small_x1_0
- MobileNetV3_small_x1_25
- MobileNetV3_large_x1_0_ssld
- MobileNetV3_large_x1_0_ssld_int8
- MobileNetV3_small_x1_0_ssld
- MobileNetV2 series[4](paper link)
- MobileNetV1 series[5](paper link)
- ShuffleNetV2 series[6](paper link)
- MobileNetV3 series[3](paper link)
- SEResNeXt and Res2Net series
- ResNeXt series[7](paper link)
- ResNeXt_vd series
- SE_ResNet_vd series[8](paper link)
- SE_ResNeXt series
- SE_ResNeXt_vd series
- Res2Net series[9](paper link)
- Inception series
- GoogLeNet series[10](paper link)
- Inception series[11](paper link)
- Xception series[12](paper link)
- HRNet series
- HRNet series[13](paper link)
- DPN and DenseNet series
- DPN series[14](paper link)
- DenseNet series[15](paper link)
- EfficientNet and ResNeXt101_wsl series
- EfficientNet series[16](paper link)
- ResNeXt101_wsl series[17](paper link)
- Other models
- AlexNet series[18](paper link)
- SqueezeNet series[19](paper link)
- VGG series[20](paper link)
- DarkNet series[21](paper link)
- ACNet series[22](paper link)
Note: The pretrained models of EfficientNetB1-B7 in the above models are transferred from pytorch version of EfficientNet, and the ResNeXt101_wsl series of pretrained models are transferred from Official repo, the remaining pretrained models are obtained by training with the PaddlePaddle framework, and the corresponding training hyperparameters are given in configs.
2.1.4. References¶
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[2] He T, Zhang Z, Zhang H, et al. Bag of tricks for image classification with convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 558-567.
[3] Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1314-1324.
[4] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[5] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[6] Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 116-131.
[7] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1492-1500.
[8] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[9] Gao S, Cheng M M, Zhao K, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE transactions on pattern analysis and machine intelligence, 2019.
[10] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[11] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]//Thirty-first AAAI conference on artificial intelligence. 2017.
[12] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
[13] Wang J, Sun K, Cheng T, et al. Deep high-resolution representation learning for visual recognition[J]. arXiv preprint arXiv:1908.07919, 2019.
[14] Chen Y, Li J, Xiao H, et al. Dual path networks[C]//Advances in neural information processing systems. 2017: 4467-4475.
[15] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708.
[16] Tan M, Le Q V. Efficientnet: Rethinking model scaling for convolutional neural networks[J]. arXiv preprint arXiv:1905.11946, 2019.
[17] Mahajan D, Girshick R, Ramanathan V, et al. Exploring the limits of weakly supervised pretraining[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 181-196.
[18] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[19] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
[20] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[21] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[22] Ding X, Guo Y, Ding G, et al. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1911-1920.