1.2. Trial in 30mins¶
Based on the flowers102 dataset, it takes only 30 mins to experience PaddleClas, include training varieties of backbone and pretrained model, SSLD distillation, and multiple data augmentation, Please refer to Installation to install at first.
1.2.1. Preparation¶
- enter insatallation dir
cd path_to_PaddleClas
- enter
dataset/flowers102, download and decompress flowers102 dataset.
cd dataset/flowers102
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/102flowers.tgz
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/imagelabels.mat
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/setid.mat
tar -xf 102flowers.tgz
- create train/val/test label files
python generate_flowers102_list.py jpg train > train_list.txt
python generate_flowers102_list.py jpg valid > val_list.txt
python generate_flowers102_list.py jpg test > extra_list.txt
cat train_list.txt extra_list.txt > train_extra_list.txt
Note: In order to offer more data to SSLD training task, train_list.txt and extra_list.txt will merge into train_extra_list.txft
- return
PaddleClasdir
cd ../../
1.2.2. Environment¶
1.2.2.1. Set PYTHONPATH¶
export PYTHONPATH=./:$PYTHONPATH
1.2.2.2. Download pretrained model¶
python tools/download.py -a ResNet50_vd -p ./pretrained -d True
python tools/download.py -a ResNet50_vd_ssld -p ./pretrained -d True
python tools/download.py -a MobileNetV3_large_x1_0 -p ./pretrained -d True
Paramters:
architecture(shortname: a): model name.path(shortname: p) download path.decompress(shortname: d) whether to decompress.
- All experiments are running on the NVIDIA® Tesla® V100 sigle card.
1.2.3. Training¶
1.2.3.1. Train from scratch¶
- Train ResNet50_vd
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/ResNet50_vd.yaml
The validation Top1 Acc curve is showmn below.
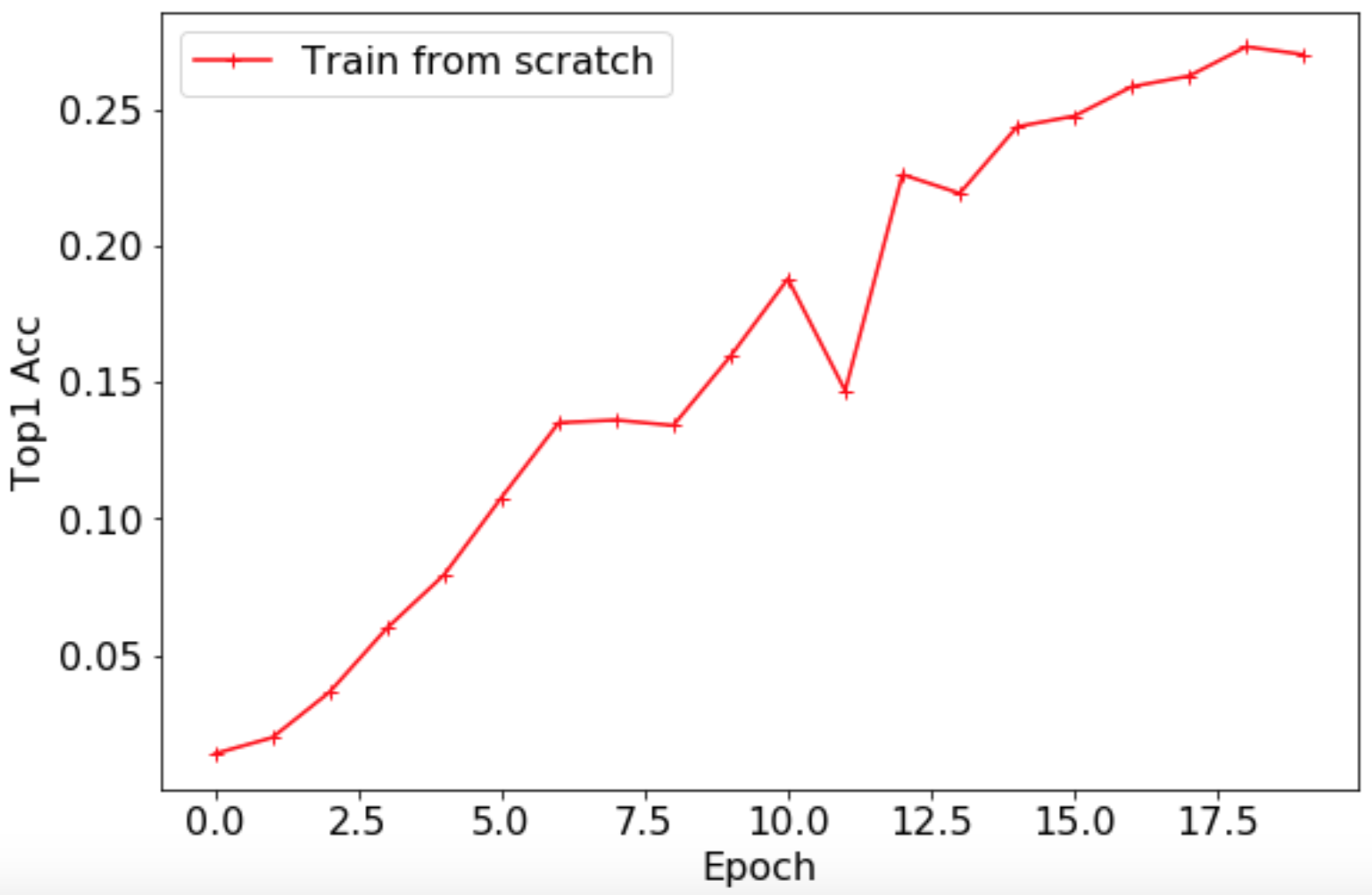
1.2.3.2. Finetune - ResNet50_vd pretrained model (Acc 79.12%)¶
- finetune ResNet50_vd_ model pretrained on the 1000-class Imagenet dataset
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/ResNet50_vd_finetune.yaml
The validation Top1 Acc curve is shown below
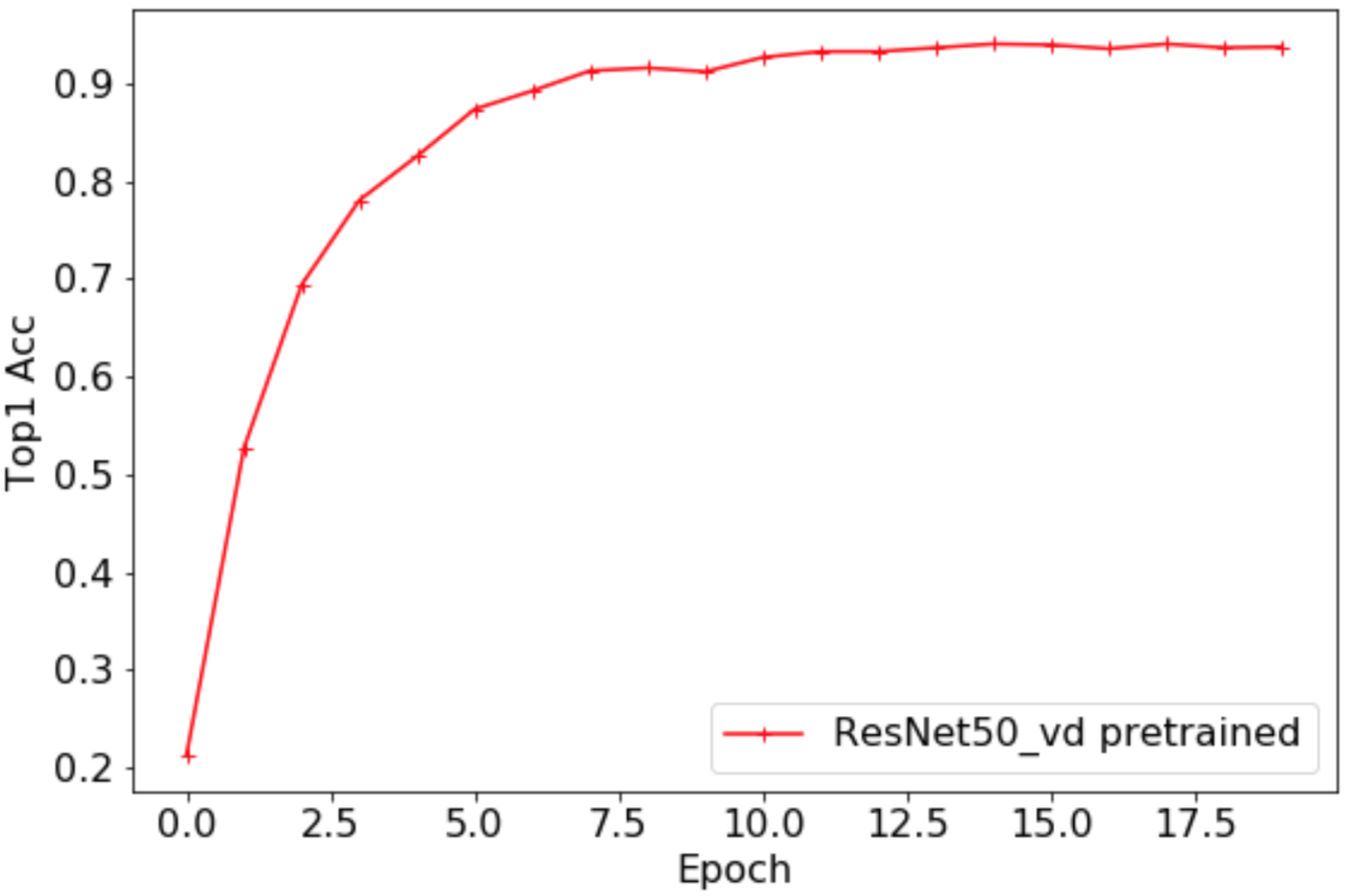
Compare with training from scratch, it improve by 65% to 94.02%
1.2.3.3. SSLD finetune - ResNet50_vd_ssld pretrained model (Acc 82.39%)¶
Note: when finetuning model, which has been trained by SSLD, please use smaller learning rate in the middle of net.
ARCHITECTURE:
name: 'ResNet50_vd'
params:
lr_mult_list: [0.1, 0.1, 0.2, 0.2, 0.3]
pretrained_model: "./pretrained/ResNet50_vd_ssld_pretrained"
Tringing script
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/ResNet50_vd_ssld_finetune.yaml
Compare with finetune on the 79.12% pretrained model, it improve by 0.9% to 95%.
1.2.3.4. More architecture - MobileNetV3¶
Training script
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml
Compare with ResNet50_vd pretrained model, it decrease by 5% to 90%. Different architecture generates different performance, actually it is a task-oriented decision to apply the best performance model, should consider the inference time, storage, heterogeneous device, etc.
1.2.3.5. RandomErasing¶
Data augmentation works when training data is small.
Training script
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/ResNet50_vd_ssld_random_erasing_finetune.yaml
It improves by 1.27% to 96.27%
- Save ResNet50_vd pretrained model to experience next chapter.
cp -r output/ResNet50_vd/19/ ./pretrained/flowers102_R50_vd_final/
1.2.3.6. Distillation¶
- Use extra_list.txt as unlabeled data, Note:
- Samples in the
extra_list.txtandval_list.txtdon’t have intersection - Because of in the source code, label information is unused, This is still unlabeled distillation
- Teacher model use the pretrained_model trained on the flowers102 dataset, and student model use the MobileNetV3_large_x1_0 pretrained model(Acc 75.32%) trained on the ImageNet1K dataset
- Samples in the
total_images: 7169
ARCHITECTURE:
name: 'ResNet50_vd_distill_MobileNetV3_large_x1_0'
pretrained_model:
- "./pretrained/flowers102_R50_vd_final/ppcls"
- "./pretrained/MobileNetV3_large_x1_0_pretrained/”
TRAIN:
file_list: "./dataset/flowers102/train_extra_list.txt"
Final training script
export CUDA_VISIBLE_DEVICES=0
python -m paddle.distributed.launch \
--selected_gpus="0" \
tools/train.py \
-c ./configs/quick_start/R50_vd_distill_MV3_large_x1_0.yaml
It significantly imporve by 6.47% to 96.47% with more unlabeled data and teacher model.
1.2.3.7. All accuracy¶
| Configuration | Top1 Acc |
|---|---|
| ResNet50_vd.yaml | 0.2735 |
| MobileNetV3_large_x1_0_finetune.yaml | 0.9000 |
| ResNet50_vd_finetune.yaml | 0.9402 |
| ResNet50_vd_ssld_finetune.yaml | 0.9500 |
| ResNet50_vd_ssld_random_erasing_finetune.yaml | 0.9627 |
| R50_vd_distill_MV3_large_x1_0.yaml | 0.9647 |
The whole accuracy curves are shown below
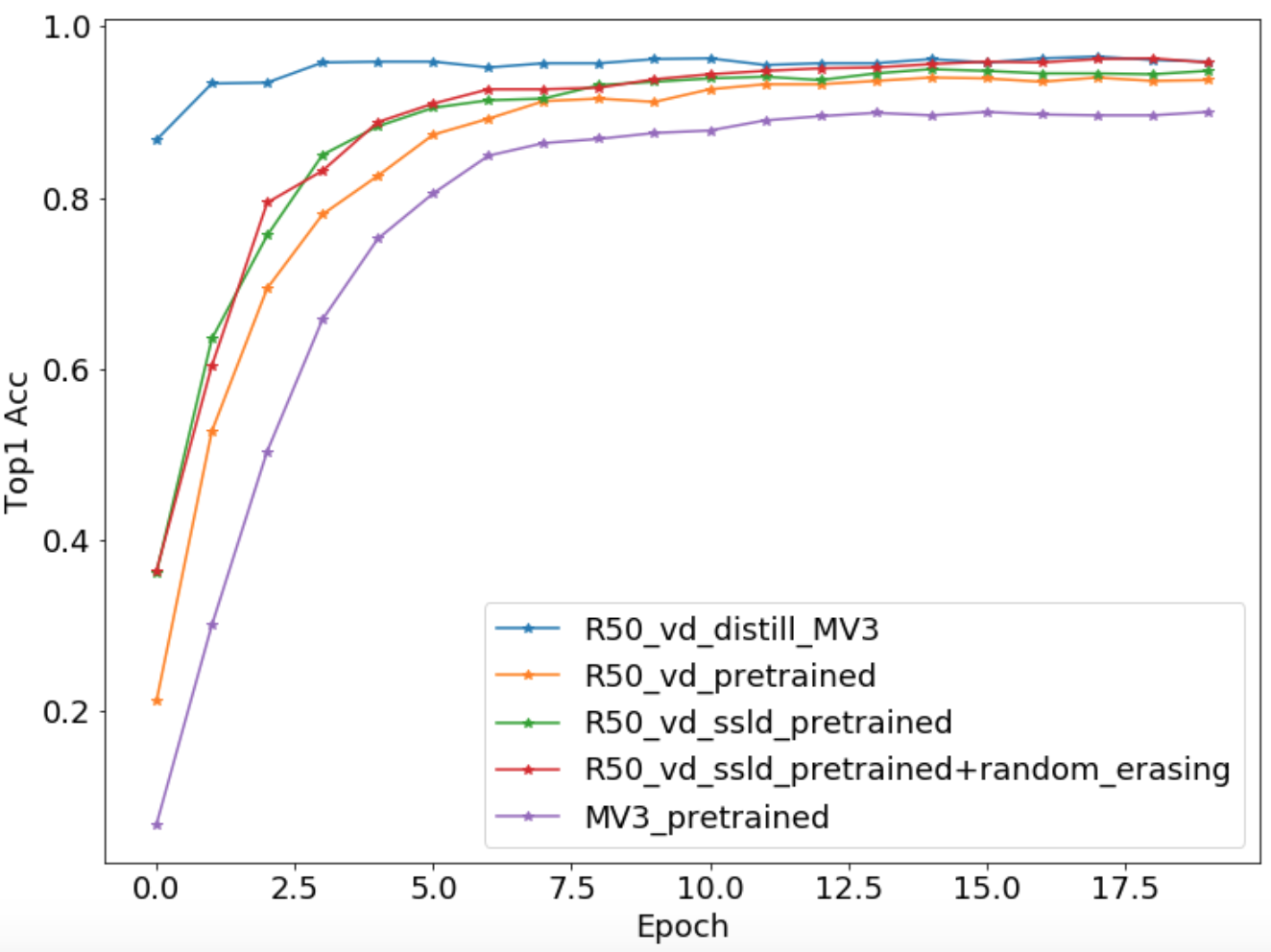
- NOTE: As flowers102 is a small dataset, validatation accuracy maybe float 1%.
- Please refer to Getting_started for more details